

10/2022
Vorschläge zur wirksameren Durchsetzung des Datenschutzrechts
1 Einführung
1.1 Problemaufriss: Chancen und Risiken
Digitale Daten prägen heutzutage unser Leben stärker als je zuvor. Sie verändern alle Lebensbereiche. Auch die Personalverwaltung wird von der Umwälzung erfasst. Unzählige Arbeitsplätze sind davon betroffen.
Der Begriff «People Analytics» bezeichnet die Personalentwicklungspraxis, bei der digitale Daten aus unternehmensinternen und -externen Quellen, die sich auf das Humankapital beziehen, mit Informationstechnologie analysiert werden, um Entscheidungen zur Steigerung des Unternehmenswerts zu treffen. Jeder Arbeitnehmer erhält dabei ein digitales Etikett, das über seine Leistung, Entwicklung, gesundheitliche Verfassung und weitere Informationen Auskunft gibt. Dadurch soll der Wert des Humankapitals, das in Bilanzen als reiner Kostenfaktor ein unvollkommenes Dasein fristet, bezifferbar gemacht werden. Zunehmend werden auch weiche Faktoren im Unternehmen vermessen, welche früher schwierig einzuschätzen waren, wie beispielsweise die Stimmung der Mitarbeitenden. Die immer feinere Granularität und Skalierbarkeit, die People Analytics ermöglicht, sind für die Personalverwaltung so bedeutsam wie die Erfindung des Mikroskops für die Biologie.
Eine Auseinandersetzung mit People Analytics ist wichtig, weil mit dem Thema sowohl Chancen als auch Risiken verbunden sind. Zu den Chancen zählt vorderhand, dass die Arbeitgeberin einen Wettbewerbsvorteil durch Effizienzsteigerung, Kostenreduktion und mehr Innovation erlangen will. People Analytics soll ebenso zum Wohle der Arbeitnehmer Transparenz und Objektivität in die Personalentscheidungen bringen, wodurch Diskriminierungen abgebaut und die Diversität im Unternehmen angereichert werden können. Beispielsweise werden bei automatisierten Einzelentscheidungen die Modellparameter bewusst ausgewählt und die Entscheidlogik hernach konsistent auf alle Fälle gleich angewendet, um das mit subjektiven Vorurteilen behaftete menschliche Ermessen zu minimieren. Auch die Mitarbeiterzufriedenheit soll durch People Analytics steigen, etwa weil die Analyse von Gesundheitsdaten sie dazu motiviert, Krankheiten gezielt vorzubeugen. Uber-Fahrer fühlen sich sicherer, wenn sie wissen, dass sie überwacht werden, als wenn sie dessen ungewiss sind. Im Endeffekt können durch die Kosteneinsparungen die Arbeitsplätze gesichert werden, und der Mensch kann sich dank neuer Technologien, die automatisierbare Prozesse übernehmen, auf die kreativen Tätigkeiten fokussieren, was in einer «Rehumanisierung» der Arbeit resultiert. Die meisten Arbeitnehmer scheinen sich nicht an den intensiver werdenden Verhaltens- und Leistungskontrollen im beruflichen Kontext zu stören.
Doch People Analytics ist auch mit Risiken verbunden. Denn die Datenanalysen können zum «Mikromanagement» von Arbeitskräften, d.h. für intensive Arbeitskontrollen mit übertriebener Detailorientierung, verwendet werden. Im Wesentlichen stellt People Analytics den Persönlichkeitsschutz der einzelnen Arbeitnehmer zur Debatte, welcher durch das Arbeits-, Datenschutz- und Diskriminierungsschutzrecht gewahrt wird. Auch die Mitwirkungsrechte der Belegschaft können von People Analytics betroffen sein. Schliesslich schürt der Umstand, dass Daten in immer mehr Arbeitsbereichen und darüber hinaus im Privatleben anfallen, ein gesellschaftliches Interesse an einem effektiven Datenschutz.
Im Folgenden ist zu klären, inwiefern sich die Forschung und Praxis mit den beschriebenen Chancen und Risiken bisher auseinandergesetzt hat und wo allenfalls Forschungslücken bestehen.
1.2 Forschungsstand und Forschungslücke
1.2.1 Vorbemerkung: Berücksichtigung internationaler Quellen
Für die vorliegende Arbeit sind das Datenschutzrecht und das Arbeitsrecht wichtig. Bzgl. datenschutzrechtlicher Fragen sind neben den schweizerischen Quellen auch diejenigen zum Datenschutzrecht der Europäischen Union und die entsprechende Literatur aus den Mitgliedstaaten zu konsultieren. Denn einerseits entfalten die europäischen Normen in gewissen Fällen eine extraterritoriale Wirkung auf die Schweiz; andererseits ist die Rechtslage hier wie dort relativ ähnlich, was nicht zuletzt darauf zurückzuführen ist, dass sowohl das schweizerische DSG als auch die europäische DSGVO inhaltlich durch die OECD-Leitlinien 1980 geprägt sind. Ferner sind Blicke auf die Rechtslage jenseits der europäischen Grenzen hilfreich, weil rund um den Erdball vergleichbare Datenschutz-Grundsätze gelten.
Es haben sich schon früh internationale Standards zur Regulierung des Datenschutzrechts, einer relativ jungen Rechtsmaterie, durchgesetzt.
Das Arbeitsrecht gehört dagegen traditionell zur Regelungshoheit des betreffenden Staats. Bzgl. arbeitsrechtlicher Fragen ist daher vorwiegend auf nationale Quellen abzustellen.
1.2.2 Behördliche Verlautbarungen
Auf Seiten der Behörden setzte sich der EDÖB zunächst mit Datenbearbeitungen beim Einsatz spezifischer Technologien auseinander: Er veröffentlichte 2012 die «Erläuterungen zur Telefonüberwachung am Arbeitsplatz» und 2013 den «Leitfaden über Internet- und E-Mailüberwachung am Arbeitsplatz (für die Privatwirtschaft)». Der im darauffolgenden Jahr erschienene «Leitfaden für die Bearbeitung von Personendaten im Arbeitsbereich (Bearbeitung durch private Personen)» erweitert den Blickwinkel, indem er einen von konkreten Technologien losgelösten generellen Überblick zur Datenbearbeitung in Arbeitsverhältnissen und insbesondere zu Überwachungs- und Kontrollsystemen am Arbeitsplatz bietet.
Das SECO, das für die Oberaufsicht über den Vollzug des ArG und der ArGV 3 zuständig ist (vgl. Art. 42 Abs. 3 ArG), hat sich gemäss eigener Auskunft direkt an den Autor der vorliegenden Arbeit bislang nicht zum Thema People Analytics geäussert.
Aus der Tätigkeit des Europarats resultierte bereits 1989 die Empfehlung No. R (89) 2 zur Bearbeitung von Personendaten, die für Anstellungszwecke verwendet werden. Im Jahr 2015 schob der Europarat die überarbeitete Empfehlung CM/Rec(2015)5 zur Bearbeitung von Personendaten im Arbeitskontext und im Jahr 2016 das dazugehörige erklärende Memorandum nach. Das Memorandum ist sowohl an öffentliche als auch an private Arbeitgeberinnen gerichtet. 2018 hat der Europarat gemeinsam mit der EU das Handbuch zum europäischen Datenschutzrecht, worin ein Unterkapitel den arbeitsplatzbezogenen Daten gewidmet ist, herausgegeben. Der EGMR fasst die EMRK-Rechtsprechung zur Überwachung am Arbeitsplatz in einem Faktenblatt von 2018 zusammen.
1.2.3 Literatur
Bzgl. Fachliteratur sollen zunächst grundlegende Werke erwähnt werden. RIESSELMANN-SAXER setzt sich in ihrer Dissertation von 2002 umfassend mit dem Thema Datenschutz im privatrechtlichen Arbeitsverhältnis auseinander. Die Autorin analysiert zunächst die rechtlichen Grundlagen, um diese am Ende auf vier bestimmte Technologien anzuwenden (Telefon-, Internet-, E-Mail- und Video-überwachung). In ihrem Werk finden sich empirische Daten zum Thema; zwischen diesen Erhebungen und den gegenwärtigen Verhältnissen am Arbeitsplatz liegen jedoch beinahe zwei Jahrzehnte.
Im Jahr 2007 widmete auch WOLFER seine Doktorarbeit dem Thema der elektronischen Überwachung des Arbeitnehmers im privatrechtlichen Arbeitsverhältnis. Hier finden sich eine Auseinandersetzung mit den betroffenen Persönlichkeitsaspekten, insbesondere mit der psychischen Integrität und der Privatheit, sowie eine Besprechung der gegenläufigen Interessen von Arbeitnehmer und Arbeitgeberin, welche bei der Frage der Rechtfertigung einer Persönlichkeitsverletzung abzuwägen sind. Gestützt darauf begutachtet der Autor die rechtliche Zulässigkeit von vier ausgewählten Überwachungssystemen (Videoüberwachung, elektronische Zeiterfassung und Zugangskontrolle, elektronische Standortermittlung ausserhalb des Betriebsgeländes sowie Überwachung der elektronischen Kommunikation).
Im deutschen Schrifttum scheinen zwei aktuellere Publikationen auf, die das komplexe Thema «People Analytics» bis in spitze Winkel abtasten: Zum einen trägt CULIKS Promotionsschrift von 2018 den Titel «Beschäftigtendatenschutz nach der EU-Datenschutz-Grundverordnung – Möglichkeit und Grenzen für Big Data-Anwendungen im Personalwesen». CULIK verwendet den Begriff «Big HR Data» und schildert das Zusammenspiel der DSGVO mit dem Arbeitsrecht und dem Diskriminierungsschutzrecht. Im Unterschied zu RIESSELMANN-SAXER und WOLFER behandelt er die auftretenden Rechtsfragen technikneutral. CULIK kritisiert, dass die europäischen und deutschen Rechtsnormen zu unbestimmt seien, um in der Praxis die erwünschte Wirkung zu erzielen.
Zur grundlegenden deutschsprachigen Literatur zählt zum andern DÄUBLERS Werk «Gläserne Belegschaften», das 2019 in der 8. Auflage erschienen ist. Dieses Handbuch zum Beschäftigtendatenschutz enthält ein Kapitel zu Big Data am Arbeitsplatz und stellt fest, dass dieses Problem «nicht bewältigt» sei, insbesondere weil man von einer informationellen Gewaltenteilung «meilenweit entfernt» sei.
Die Konsultation rechtsvergleichender Beiträge lohnt sich, weil Datenbearbeitungen häufig Bezüge zu verschiedenen Rechtsordnungen aufweisen und Rechtsordnungen weltweit mit den gleichen Technologien umgehen müssen. OTTO vergleicht das US-amerikanische, das europäische und das kanadische Modell des Datenschutzes in Arbeitsverhältnissen in ihrer 2016 erschienenen Monografie. Einen Blick auf die australische Rechtsordnung gewähren O’ROURKE, PYMAN und TEICHER im Aufsatz «The right to privacy and the conceptualisation of the person in the workplace: a comparative examination of EU, US and Australian approaches» von 2007.
Diverse Autoren betrachteten in der jüngeren Vergangenheit einzelne Segmente von People Analytics, seien es bestimmte verwendete Technologien oder gewisse Verwendungszwecke. Zu erwähnen sind namentlich die rechtswissenschaftlichen Dissertationen von: NEU (Der Einsatz moderner Kommunikationsmittel am Arbeitsplatz im Spannungsverhältnis zum Arbeitnehmerdatenschutz, 2012; mit einem Schwerpunkt auf Telefon-, Internet- und E-Mail-Daten), STEIGERT (Datenschutz bei unternehmensinternen Whistleblowing-Systemen, 2012), GASCHER (Zulässigkeit eines Datenabgleichs zur Aufdeckung von Straftaten von Arbeitnehmern, 2013), OWSCHIMIKOW (Datenscreening zwischen Compliance-Aufgabe und Arbeitnehmerdatenschutz, 2013), MEYER-MICHAELIS (Die Überwachung der Internet- und E-Mail-Nutzung am Arbeitsplatz, 2014; unter Berücksichtigung der Rechtslage in den USA), ZHANG (Videoüberwachung von Arbeitnehmern, 2016; einschliesslich eines Rechtsvergleichs zwischen Deutschland und China) und BROY (Der Umgang mit Bewerberdaten aus Internetquellen, 2017). Ferner darf die Monografie von BYERS (Mitarbeiterkontrollen, Praxis im Datenschutz und Arbeitsrecht, 2016) nicht vergessen werden. Die Forschungsergebnisse von HÖLLER und WEDDE (Die Vermessung der Belegschaft, 2018; mit einem Fokus auf dem unternehmensinternen sozialen Graphen) sowie diejenigen von CUSTERS und URSIC (Worker privacy in a digitalized world under European law, 2018) runden den Spiegel der Spezialliteratur ab.
Die Literaturanalyse zeigt, dass sich für das Phänomen der Personalanalysen mit neuen Technologien – wohl gerade wegen der jungen Entwicklung dieser Technologien – noch kein einheitlicher Begriff durchgesetzt hat. Am häufigsten anzutreffen sind die Bezeichnungen «People Analytics» und «HR Analytics». Aber auch «Workforce Analytics», «Talent Analytics», «Human Capital Analytics», «Workplace Analytics» und weitere Namensgebungen sind im Umlauf. Der Wortteil «Analytics», zu Deutsch «Analytik», bedeutet wörtlich die «Kunst des Auflösens» (altgr. ἀναλύτική (τέχνη), «analytikḗ [téchnē]») und bezeichnet vorliegend das Sezieren und Interpretieren von Datensätzen. Angesichts der starken Verbreitung des Ausdrucks «People Analytics» wird in der vorliegenden Arbeit dieser Begriff in der Einzahl verwendet. Nichtsdestotrotz trifft «Workforce Analytics» den Vorgang der Big Data-Analysen am Arbeitsplatz wohl präziser, weil die «Workforce» (im Gegensatz zu «People») einen spezifischen Bezug zum Arbeitsplatz herstellt. Ausserdem umfasst sie die Auswertung der gesamten Arbeitskraft, die zum Erfolg des Unternehmens beiträgt (Festangestellte, Temporärmitarbeiter, Talente, nicht angestellte Vertragspartner, Freelancer, Outsourcing-Dienstleister), einschliesslich der künftig zu erwartenden wachsenden Zahl von Robotern am Arbeitsplatz. Deutsche Übersetzungen, etwa «Personalanalytik», sind ungleich seltener als die englischen Termini anzutreffen.
1.2.4 Forschungslücke
Es besteht erheblicher Diskussionsbedarf zu People Analytics. Forschungslücken zeigen sich in folgenden Bereichen:
Die beiden am schweizerischen Recht orientierten Dissertationen von RIESSELMANN-SAXER und WOLFER sind zu Beginn des 21. Jh. entstanden. Begriffe wie «People Analytics», «Algorithmen» oder «Big Data», die mittlerweile das Forschungsfeld prägen, fehlen dort noch. Auch neu hinzugetretene technologische Ausstattungen wie RFID, Roboter oder Wearables bleiben weitgehend ausgeklammert. Vorliegend ist für den Einstieg ins Thema eine aktualisierte Übersicht zu den Überwachungstechnologien geboten. Diese ist idealerweise beständiger und umfassender als bei den erwähnten beiden Autoren, die sich je auf vier damals verbreitete Technologien beschränken. Das Vorhaben soll gelingen, indem nicht primär die Technologien an sich beschrieben werden, sondern zu welchen Zwecken sie im Verlauf eines Arbeitnehmer-Lebenszyklus Verwendung finden.
Zudem sind empirische Zahlen zur praktischen Verbreitung und Anwendung von People Analytics in schweizerischen Unternehmen notwendig. Seit RIESSELMANN-SAXER (2002) hat, soweit ersichtlich, niemand mehr eine systematische Er-hebung vorgenommen.
Die beiden schweizerischen Doktorarbeiten von RIESSELMANN-SAXER und WOLFER sind lange vor Inkrafttreten der DSGVO und des rev-DSG entstanden. Die geänderten Rechtsgrundlagen (die DSGVO und die sich abzeichnenden Bestimmungen gemäss dem E-DSG bzw. rev-DSG) sind in die vorliegende Untersuchung von People Analytics einzubeziehen.
Die jüngeren Werke, namentlich diejenigen von CULIK und DÄUBLER sowie die zahlreichen segmentalen Titel, ergeben zusammengenommen relativ vollständig Auskunft zu den Rechtslagen in allen Situationen, die durch People Analytics entstehen können. Doch der grosse Umfang der einschlägigen Fachliteratur zu diesem Thema zeigt, dass das Datenschutzrecht nicht selbsterklärend ist und daher auch nicht konsequent durchgesetzt werden kann. Dies ist problematisch, weil Datenaufzeichnungen zunehmend das gesamte Arbeitsverhältnis mitbestimmen. Gesucht ist ein Rezept zur besseren Durchsetzung des Datenschutzrechts.
Während seines Forschungsaufenthalts am Berkman Klein Center for Internet & Society an der Harvard University in Cambridge (Massachusetts, USA) im Frühjahr 2019 hat der Autor zudem den Eindruck erhalten, dass People Analytics im angloamerikanischen Raum weiter fortgeschritten ist als in Festlandeuropa. Beispielsweise gehören Programme zur Analyse der Gesundheit der Arbeitnehmer in amerikanischen Grossunternehmen zum Standard. Doch hat sich auch ergeben, dass die Rechtsprobleme, die People Analytics verursacht, weltweit ähnlich sind, und vor allem, dass den Datenschutz-Idealen in der Praxis überall mangelhaft nachgelebt wird. So wurde etwa Facebook im Jahr 2019 in den USA eine rekordhohe Busse von USD 5 Milliarden auferlegt wegen des Cambridge Analytica-Datenskandals, der weltweit Bekanntheit erlangt hat.
1.3 Zielsetzung und Forschungsfrage
Vor dem skizzierten Hintergrund verfolgt die Abhandlung das folgende Ziel: Es sollen Vorschläge aufgezeigt werden, wie in der privatrechtlichen People Analytics-Praxis die Einhaltung des Datenschutzrechts sichergestellt werden kann.
Zur Zielgruppe gehört zunächst die Rechtswissenschaft. Für sie ist Grundlagenforschung zu betreiben, da es sich bei der mangelhaften Durchsetzung des Datenschutzrechts um ein strukturelles Problem handelt. Die Grundlagenforschung ist auch angezeigt, weil sich der Rechtsrahmen für Datenbearbeitungen ständig ändert und somit nur die grundlegenden Bestimmungen von Dauer sind. Ganz offensichtlich richtet sich die Doktorarbeit an die Personalverantwortlichen in den Betrieben, da sie letztlich das Datenschutzrecht anwenden. Um ihre Lage zu verstehen und sie in ihrer Sprache anzureden, müssen empirische Daten zu People Analytics in die Arbeit einfliessen. Ebenso wird die Politik angesprochen, die im Begriff ist, das DSG zu revidieren. Diesem breiten Publikum dienen die konzisen Zwischenergebnisse und Ergebnisse dazu, mit wenig Zeit den Einstieg in die komplexe Thematik zu finden und die zentralen Botschaften mitzunehmen.
Aufgrund des Forschungsziels lautet die zentrale, übergeordnete Forschungsfrage:
FORSCHUNGSFRAGE: Wie könnte eine künftige Neuausrichtung des privatrechtlichen Datenschutzrechts aussehen, bei welcher die Rechtsdurchsetzung ex ante und ex post im Zusammenhang mit People Analytics besser gewährleistet wäre als heute?
Um diese Hauptfrage zu beantworten, werden vorgängig in kausal zusammenhängender Reihenfolge die nachstehenden untergeordneten acht Vorfragen angegangen:
- Was ist People Analytics und was ist daran neu im Vergleich zu früheren Überwachungspraktiken an den Arbeitsplätzen?
- Welche Rechtsprobleme ergeben sich aus People Analytics?
- Welche Rechtsgebiete sind für People Analytics relevant?
- Welchen Zweck verfolgt das DSG im Hinblick auf People Analytics?
- Welche People Analytics-Anwendungen erfasst das DSG und welche Datenbearbeitungsregeln stellt es für People Analytics in privatrechtlichen Arbeitsverhältnissen auf?
- Welche Rechtfertigungsmöglichkeiten bestehen für allfällige Datenschutzverletzungen?
- Warum hat die zivilrechtliche Individualklage ihre Rolle bei der Durchsetzung des Datenschutzrechts bis heute nicht erfüllen können?
- Wie können Gruppen und/oder Behörden ihre Interessen beim Datenschutz wirksam einbringen, um zur Rechtsdurchsetzung beizutragen?
1.4 Abgrenzung der Forschungsfrage
Die vorliegende Arbeit untersucht in sachlicher Hinsicht die rechtlichen Rahmenbedingungen für People Analytics. Gegenstand der Analyse sind privatrechtliche Arbeitsverhältnisse. Öffentlich-rechtliche Anstellungsverhältnisse werden ausgeklammert. Vertragsverhältnisse, in denen arbeitnehmerähnliche Stellungen vorkommen, wie beispielsweise mit freien Mitarbeitern (Freelancer), werden nur beachtet, soweit sich daraus Erkenntnisse für den Arbeitsvertrag unter Privaten gewinnen lassen.
Räumlich bezieht sich die Abhandlung auf Rechtsverhältnisse in der Schweiz, d.h., das arbeitgebende Unternehmen hat Sitz in der Schweiz und der Arbeitsort liegt ebenfalls innerhalb dieses nationalen Territoriums.
In personeller Hinsicht fallen die Hauptrollen bei People Analytics dem Arbeitnehmer und der Arbeitgeberin zu. Unter dem Begriff des Arbeitnehmers wird vorliegend der Angestellte in einem Arbeitsvertrag (Art. 319 ff. OR) verstanden. In die Betrachtung eingeschlossen werden auch Stellenbewerber und ehemalige Mitarbeiter, da sie sich weitgehend auf den Datenschutz von Arbeitnehmern berufen können. Als «Arbeitgeberin» fallen sowohl eine natürliche (Art. 11 ff. ZGB) als auch eine juristische Person (Art. 52 ff. ZGB) in Betracht. Datenschutzrechtlich wird die Arbeitgeberin als verantwortliche Stelle mit Entscheidungsgewalt angesehen (vgl. Art. 4 lit. i E-DSG, Art. 5 lit. j rev-DSG, Art. 4 Nr. 7 DSGVO), unabhängig davon, ob sie die eigentliche Datenbearbeitung vornimmt. Folglich wird nicht näher auf Konstellationen eingegangen, bei denen Dritte an Stelle der Arbeitgeberin handeln, wie beispielsweise bei der Auftragsdatenbearbeitung und beim Outsourcing (vgl. hierzu Art. 10a DSG, Art. 8 E-DSG, Art. 9 rev-DSG). Der Begriff der Arbeitgeberin schliesst vorliegend Unternehmen jeder Grösse ein. People Analytics findet zwar vorwiegend in grossen Unternehmen statt. Jedoch gelten die Datenschutz-Grundsätze auch für Familienbetriebe, da dort die gleichen Datenschutzprobleme auftreten können.
1.5 Methodik der begleitenden empirischen Datenerhebung
Die vorliegende theoretische Auseinandersetzung mit People Analytics, die auf einer Analyse von Gesetz, Materialien, Literatur und Rechtsprechung beruht, wird an den geeigneten Stellen durch die empirischen Daten ergänzt, die der Autor zusammen mit dem Forschungsteam des NFP75-Projekts erhoben hat. Dieses basierte auf einem Forschungsdesign mit gemischten Methoden verteilt über mehrere Module (mixed methods research design).
Das erste Modul widmete sich der Frage «Welche People Analytics-Technologien kommen in der Praxis vor?» und begann mit einer qualitativen Untersuchung, bei der insgesamt 27 Experten zu People Analytics in der Schweiz befragt wurden. Es kam Interviewmaterial von 30 Stunden zusammen. Daraus resultierte eine Beschreibung des Phänomens, und die verschiedenen Anwendungen wurden in Kategorien eingeteilt.
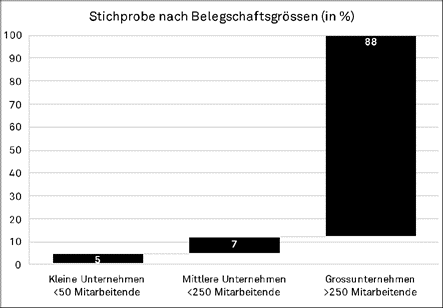
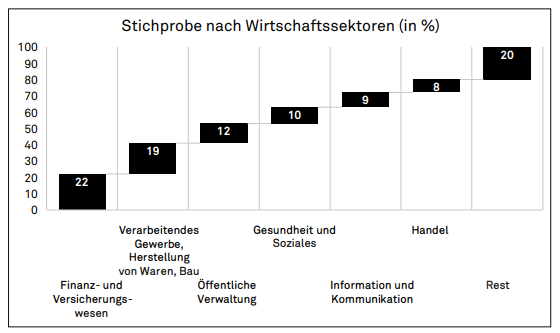
Im zweiten Modul galt es, herauszufinden, wie verbreitet People Analytics in der Schweiz ist. Auch war es von Interesse, zu erfahren, wie stark sich die Personalverantwortlichen der rechtlichen Schranken von People Analytics bewusst sind und wie sie damit umgehen. Weiter sollte festgestellt werden, wie verschiedene Stakeholdergruppen am Prozess mitwirken und welche ethischen Fragestellungen auf welche Weise diskutiert werden. Methodisch eignete sich hierfür eine quantitative Online-Umfrage. Diese stand während eines Zeitraums von zwei Monaten zur Teilnahme offen (15.05. bis 13.07.2018). Angeschrieben wurden 1’185 Personalverantwortliche von Unternehmen mit Sitz in der Schweiz. Von ihnen haben 158 die Fragen vollständig beantwortet. Diese Stichprobe setzt sich zu zwei Dritteln aus Angehörigen des Top- oder Senior-Managements und zu einem Drittel aus Personen des Middle- oder Junior-Managements zusammen. Überwiegend sind grosse Unternehmen dabei (siehe Abb.1). Die Branchenstruktur ist ungefähr repräsentativ für die Schweiz, wobei das Finanz- und Versicherungswesen etwas überrepräsentiert ist (siehe Abb.2).
1.6 Aufbau
Aufgrund ihrer Ziele und Fragen gliedert sich die Arbeit in acht Teile und beginnt mit der vorliegenden Einführung.
- Anschliessend gilt es, das Phänomen People Analytics zu beschreiben, d.h. aufzuzeigen, was daran im Vergleich zu früheren Überwachungen am Arbeitsplatz neu ist und dass es bereits eine Verbreitung erlangt hat, die es zu einem relevanten Thema macht. Im Unterkapitel 2.2findet der Leser die Erklärungen der technischen Begriffe, die in dieser Arbeit vorkommen.
- Im dritten Teil sind die Rechtsprobleme, die People Analytics aufwirft, darzulegen. Sie geben den Anstoss für die nachfolgende juristische Untersuchung des Phänomens.
- Die rechtliche Untersuchung beginnt mit einer Übersicht der relevanten Rechtsbestimmungen und der Schutzlücken in den Geltungsbereichen der Rechtserlasse.
- Im fünften Kapitel wird auf das Datenschutzrecht näher eingegangen, das bei People Analytics eine eminente Stellung einnimmt. Hierzu gehören eine Ergründung des Zwecks des DSG und die Betrachtung der Pflichten der Arbeitgeberin, welche sich aus den Datenbearbeitungsregeln und -rechtfertigungsgründen ergeben.
- Spiegelbildlich zu den Pflichten der Arbeitgeberin stehen die Rechte der Individuen, der Arbeitnehmervertretung und der Behörden zur Durchsetzung des Datenschutzrechts.
- Das siebte Kapitel widmet sich ganz der Beantwortung der Forschungsfrage. Es wird sich zeigen, dass das Datenschutzrecht weder von der Arbeitgeberin ex ante genügend umgesetzt noch von der Gegenseite ex post durchgesetzt wird. Damit hat das Datenschutzrecht ein Glaubwürdigkeitsproblem, weil es in der Praxis nicht gelebt wird. Nach der vorliegend entwickelten These könnten eine Professionalisierung und eine Demokratisierung zur wirksameren Durchsetzung des Datenschutzrechts führen. Diese These wird im siebten Kapitel erklärt.
- Am Schluss werden alle essenziellen Ergebnisse, die einen neuen Beitrag zur Forschung darstellen, auf den Punkt gebracht.
2 Phänomenbeschreibung
2.1 Übersicht
Als Einstieg ins Thema gilt es, den Forschungsgegenstand, People Analytics, zu beschreiben. Zunächst wird der zweite Wortteil – «Analytics» – erörtert, um jene technischen Begriffe zu erläutern, die in den späteren Kapiteln fallen werden. Sodann wird mit Bezug auf den ersten Wortteil – «People» – dargelegt, zu welchen Zwecken die Technologien verwendet werden und wie dabei Mensch und Technik interagieren. Die Analyse der gegenwärtigen und möglichen künftigen Verbreitung von People Analytics wird die praktische Relevanz des Themas unterstreichen. Basierend auf diesen einleitenden Beobachtungen sind die Kernelemente herauszuschälen, durch die sich People Analytics von früheren Überwachungspraktiken an den Arbeitsplätzen unterscheidet.
2.2 Technische Begriffserklärungen
2.2.1 Daten-Lebenszyklus
Als Gedankenstütze bei der Betrachtung der technischen Aspekte von People Analytics dient der Daten-Lebenszyklus. Dieser besteht aus vier Phasen, (1) angefangen bei der Datenbeschaffung, (2) über die Datenanalyse und (3) die Nutzung der Daten mit deren Wirkung auf die Umwelt bis hin zur (4) Löschung oder gegebenenfalls Wiederverwendung der Daten (siehe Abb. 3).
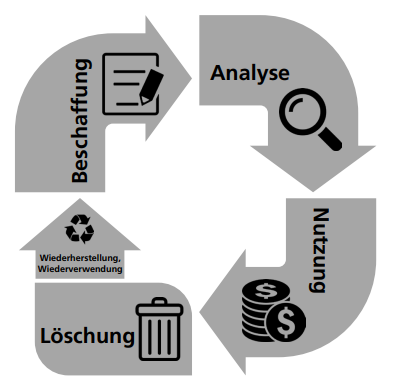
Im Folgenden ist in Bezug auf die Datenbeschaffung zu klären, was überhaupt Daten sind. Zudem sind die für die Datenerhebung erforderlichen physischen Komponenten (Hardware) zu beschreiben. In der Phase der Datenanalyse stehen die verwendeten Algorithmen bzw. Programme (Software) im Zentrum. Bei der Datennutzung leuchtet der Begriff «Big Data» auf, welcher auch Ausgangspunkt des NFP75-Projekts war. Schliesslich gibt es in der vierten Phase zwei Alternativen: Entweder werden die Daten gelöscht oder aber sie werden wiederverwendet, wodurch der Daten-Lebenszyklus von Neuem beginnt.
2.2.2 Daten
a) Daten und Information
Das Wort «Datum» bedeutet wörtlich «das Gegebene». Diese etymologische Herkunft widerspiegelt sich im deutschen Wortlaut des DSG, wonach Daten «Angaben» bezeichnen (Art. 3 lit. a DSG, Art. 4 lit. a E-DSG, Art. 5 lit. a rev-DSG). Datenschutzrechtlich relevant sind die Angaben, wenn sie sich auf eine bestimmte oder bestimmbare Person beziehen (vgl. Art. 3 lit. a DSG, Art. 4 lit. a E-DSG, Art. 5 lit. a rev-DSG).
In der französischen und der italienischen Fassung des DSG sind Daten gleichbedeutend mit Informationen («informations», «informazioni»). Auch das europäische Recht setzt «Daten» und «Informationen» gleich (Art. 4 Nr. 1 DSGVO). Die Rechtswissenschaft und Rechtspraxis kennen keine eigenen, einheitlichen Begriffe des Datums und der Information, sondern verwenden diese Termini gemäss dem üblichen, alltäglichen und mehrdeutigen Sprachverständnis.
Ein Teil der Lehre unterscheidet die beiden Begriffe «Daten» und «Information» qualitativ, indem Daten als das Rohmaterial und Information als das bearbeitete, nutzbare Wissen bezeichnet werden. Information schliesst dabei den Sinn ein, der den Daten durch eine Analyse verliehen wird. Gemäss DRUEY erhält Information erst rechtliche Relevanz, wenn unter ihrem Empfänger ein Mensch verstanden wird. Nach der hier vertretenen Auffassung können sich aber auch rechtliche Fragen ergeben, wenn eine Maschine Informationsempfängerin und -verarbeiterin ist. Dieses breitere Informationsverständnis wird mit Blick auf das aufkommende Internet der Dinge künftig an Bedeutung gewinnen.
Eine Information ist in sich noch kein Wert. Information ist als Wertchance zu verstehen, die sich je nach Ausgestaltung der Information im Verhältnis zu ihrem Adressaten verwirklicht. Für die Realisierung des Werts ist somit ein geeigneter Empfänger erforderlich, der die Chance nutzt. Um die im Zusammenhang mit Daten oft anzutreffende Wasser-Metapher aufzugreifen: Ein Stausee enthält Wasser (Daten) mit einer physikalischen Lageenergie (Wertchance); Letztere kann aber nur jemand freisetzen, der das Kraftwerk betätigen und Wasser durch die Turbinen schnellen lassen kann. Das Verständnis von Information als Wertchance ist relevant bei der Bestimmung des Geltungsbereichs des DSG. Für dessen Anwendbarkeit kann es entscheidend sein, ob eine Datenbearbeiterin zum Zweck der Wertschöpfung gewisse anonyme Daten durch Re-Identifizierung einer Person zuordnen will oder nicht.
Es gibt weitere Ausprägungen der Begriffe «Daten» und «Information», die vorliegend nur in Kürze zu erwähnen sind. In der Diskussion um ein mögliches Dateneigentum wird Information als Objekt beschrieben, das als strukturelle, syntaktische oder semantische Information existieren kann. Auf diese Dreiteilung muss jedoch nicht näher eingegangen werden, weil vorliegend ein Dateneigentum für das Schweizer Recht abgelehnt wird. Ferner kann Information als Vorgang zwischen einem Sender und einem Empfänger dargestellt werden und kommt dabei dem Begriff «Kommunikation» nahe. Weniger verbreitet ist das Verständnis von Information als Zustand der Kenntnis; es kommt in der Wendung «Stand der Information» zum Ausdruck. Schliesslich differenziert ein Teil der Rechtsliteratur quantitativ, indem ein Datum die kleinste Einheit von Information darstelle.
Der doppeldeutige Begriff des «Informationsrechts» kann sowohl das «Recht auf Information» als auch das «Recht der Information» bezeichnen. Ersteres meint den subjektiven Anspruch darauf, informiert zu werden, und steht somit gegensätzlich zum Recht auf Geheimhaltung. Dieses Verständnis von «Informationsrecht» wird bei der Besprechung der Mitwirkungsrechte der Arbeitnehmer bedeutsam werden. Das Recht der Information betrifft dagegen das Recht im objektiven Sinn, das sich in seiner Gesamtheit mit Information befasst. Die Informations-Rechtswissenschaft befasst sich einerseits mit der Analyse der rechtlichen Rahmenbedingungen und Bestimmungen zu Informationserzeugung, -verteilung, -austausch, -zugang und -nutzung in einem bestimmten gesellschaftlichen (z.B. dem wirtschaftlichen, kulturellen oder politischen) Subsystem. Andererseits erforscht die Informations-Rechtswissenschaft die dynamischen Veränderungen der Informations- und Kommunikationstechnologien und -prozesse sowie deren Auswirkungen auf das Recht. Auch dieses zweite Verständnis von Informationsrecht interessiert vorliegend, und zwar mit Blick auf das Subsystem Arbeitsplatz.
b) Digitalisierung und Datafizierung
Im Lichte der vorstehenden Ausführungen sind Daten nicht zwingend digitale Einheiten (Bits) im Sinne der Informatik, weil auch andere Repräsentationen von Information möglich sind. Es ist jedoch eine Tatsache, dass heutzutage schätzungsweise über 98 Prozent der Daten digital aufgezeichnet werden.
Die Digitalisierung (digita(li)sation) bezeichnet die Verwandlung analoger Daten zu digitalen, die in einer maschinell lesbaren, binären Sprache aus Nullen und Einsen gefasst sind. Die Digitalisierung bedeutet noch nicht, dass die Daten kategorisiert sind: Eine eingescannte Buchseite ist zwar digital, der Text aber lässt sich noch nicht auf bestimmte Stichwörter hin automatisch durchsuchen.
Die Datafizierung (datafication) ist der nächste Schritt, der zur Verwertung von Daten erforderlich ist. Datafizieren bedeutet, Daten in ein quantifiziertes Format zu setzen, sodass sie kategorisiert und interpretiert werden können. Um beim obigen Beispiel zu bleiben: Der eingescannte Text ist erst datafiziert, wenn ein Texterkennungs-Programm (optical character recognition, OCR) das digitale Bild in einzelne Buchstaben zerlegt hat. In einem datafizierten Datensatz lässt sich, wie in einem Register, nach Suchbegriffen nachschlagen. Die Tatsache, dass sich die Menschheit zusehends dem «onlife» nähert, d.h. einer Existenz, die durch Informationstechnologie vermittelt wird, führt dazu, dass das gesamte Leben datafiziert und durchsuchbar werden wird.
Die Datafizierung steht als Begriff unabhängig von Digitalisierung und ist ihrem Wesen nach auch älter: Eine Ausprägung von Datafizierung ist beispielsweise das Koordinatensystem aus Längen- und Breitengraden der Erde, dessen Erfindung auf Eratosthenes von Kyrene (276/273–194 v.Chr.) zurückgeht: Über ein System von Gitterlinien zur Standortbestimmung wird es möglich, jede Position in einem numerischen Format aufzuzeichnen, zu kategorisieren oder zu suchen.
Nach der im Wesentlichen immer noch gleichen Logik überwachen Arbeitgeberinnen heute ihre Fahrzeugflotten und die Aufenthaltsorte ihrer Arbeitnehmer.
Die Datafizierung wirkt als Katalysator bei der Realisierung der Wertchancen, die in Informationen stecken. Daten kommen nun aufbereitet als «Mahlgut für die Analysemühle» daher. Wirtschaftliche Impulse entstehen, wenn Bewegung in die Daten kommt. Johannes Gutenbergs (1400–1468) Buchdruckerfindung hat gezeigt, wie einflussreich gedruckte Information sein kann, wenn sie weit durch die Gesellschaft gestreut wird. Der durch die Datafizierung in Gang gesetzte Informationsfluss ist historisch vergleichbar mit Gütertransportachsen, die Volkswirtschaften zum Erblühen brachten, wie die Seidenstrasse, das römische Fernstrassennetz ausgehend von der Via Appia oder die britische Flotte.
2.2.3 Ausgewählte physische Komponenten und Computerinfrastruktur
a) Sensoren, Wearables und Roboter zur Datenbeschaffung
Die Beschaffung der für People Analytics erforderlichen Daten gelingt mit sog. Sensoren (von lat. sentire: fühlen, empfinden, wahrnehmen). Es handelt sich dabei um technische Bauteile, die bestimmte physikalische oder chemische Eigenschaften der Umgebung erfühlen und in ein elektrisches Signal umformen. Beispielsweise registrieren Infrarot-Kameras die Wärme und GPS-Sensoren empfangen Radiowellen von Satelliten. Mit beiden Techniken lassen sich auch Arbeitnehmer orten.
Vermehrt kommen Sensoren vor, die am oder im Körper getragen werden (wearables bzw. wearable computers). Wearables können die Form von Accessoires (z.B. Kopfhörer, Armbänder, Brillen, oder Zahnbürsten) annehmen oder in die Kleidung eingenäht werden. Teils werden sie als Tattoo oder Folie auf der Haut getragen oder als Implantate unter die Haut gespritzt. Die Arbeitgeberin kann Wearables grundsätzlich als Arbeitsmittel oder Fitnesstracker einsetzen. Wertvoll sind Wearables für die Arbeitgeberin, weil sie Informationen direkt von den Mitarbeitern liefern (user data). Dies vermittelt eine grössere Einsicht in das Humankapital als mittelbare Daten, etwa dazu, wie eine Maschine bedient wurde (use data). Das Speichersystem eines Wearable setzt sich aus dem lokalen (dem Wearable selbst) und einem externen Speicherort (Smartphone, Computer, Cloud) zusammen. Die externe Komponente zeigt in der Regel über ein Anwendungsprogramm (Applikation, App) die Datenauswertung an. Beispielsweise stellt die App «Happiness Planet» auf dem Mobiltelefon die Daten dar, die das noch näher vorzustellende «Happiness Meter»-Halsband von Hitachi aufzeichnet.
Menschen arbeiten zusehends mit Robotern zusammen. Dies erfordert einen Informationsaustausch über die Sensoren der Roboter. Exosuits und Exoskelette ertasten so die anthropometrischen Merkmale jedes individuellen Arbeitnehmers, um sich dessen Schritt-, Arm- und Rückenlänge anzupassen. Roboter haben aber nicht nur Sensoren zur Wahrnehmung; sie können diese Wahrnehmung auch mittels Datenanalyse prozessieren (think) und gestützt darauf physisch handeln (navigieren, etwas bewegen) oder nichtphysische Funktionen ausführen (warnen, empfehlen, entscheiden) (act). Beispielsweise die Kiva-Roboter in den Warenlagern von Amazon transportieren Kunststoffbehälter voller Artikel zu Arbeitnehmern, die darauf die Bestellung ausführen.
b) Internet als Medium zur Datenübertragung
Der Begriff des Internets bedeutet «miteinander verbundene Netzwerke» (inter-connected networks). Als Geburtsstunde des Internets gilt das Jahr 1969. DenDurchbruch zum populären Massenmedium schaffte das Internet aber erst rund zwanzig Jahre später dank zweier Entwicklungen: Einerseits gelang Ende der 1980er-Jahre die Verbindung des Internets mit den E-Mail-Diensten, wodurch der Nachrichtenversand für die breite Öffentlichkeit zu kommerziellen Zwecken möglich wurde. Andererseits präsentierte der Informatiker Tim Berners-Lee 1989 den Internetdienst World Wide Web (WWW), dessen disruptive Neuerung darin bestand, dass es ausser Text auch beliebige andere Informationen wie Zeichnungen oder Bilder transportieren konnte. Heute fungiert das Internet als das Medium, worüber aufgezeichnete Daten in breitem Stil ausgetauscht werden.
Das Internet der Dinge (internet of things, IoT) beschreibt ein drahtgebundenes oder drahtloses Netzwerk von Geräten, die über eingebettete Sensoren miteinander kommunizieren, wobei die Daten via Internet übertragen werden. Mittlerweile gibt es mehr ans Internet gebundene Geräte als Menschen auf der Erde. Ruft man sich die Wearables, die Arbeitnehmende an und in sich tragen (werden), in Erinnerung, so weitet sich das Phänomen zu einer digitalen Vernetzung aller Werker, Werkzeuge und Werkstücke im Produktionsprozess und über Unternehmensgrenzen hinweg aus. Dies generiert ein «Internet der Dinge und der Menschen». Diese netzwerkartige Architektur führt dazu, dass Daten über die Mitarbeiter in exponentiellem Ausmass zunehmen werden. Wir erleben eine vierte industrielle Revolution; in der Welt des sog. Arbeitens 4.0 verschmelzen die physische und die digitale Sphäre miteinander.
c) Cloud-Computing
Die Rechnerwolke (Cloud-Computing) ist eine IT-Infrastruktur, die als Dienstleistung angeboten wird. Die Infrastruktur besteht aus einem Netzwerk von Servern. Die Kunden beziehen Speicherplatz, Rechenleistung oder Anwendungssoftwares. Diese Dienstleistungen sind über eine technische Schnittstelle verfügbar, beispielsweise über das WWW und einen zugehörigen Webbrowser. Charakteristisch für Cloud-Computing ist, dass die Daten von überall her bzw. von irgendeinem Gerät aus bezogen werden können.
2.2.4 Algorithmen
a) Zum Begriff «Algorithmus»
Als Algorithmus gilt allgemein die mathematische Logik hinter jeder Art von System, das Aufgaben ausführt oder Entscheidungen trifft. Algorithmen gab es lange vor der Digitalisierung, etwa zur technischen Steuerung von Maschinen. Das Wort «Algorithmus» ist eine Verballhornung von «al Chwarizmi», dem Familiennamen des persischen Rechenmeisters und Astronomen Muhammad ibn Musa al Chwarizmi (780–835/850 nach julianischem Kalender). Von seinem Werk ist die lateinische Übersetzung erhalten geblieben, die den Titel Algoritmi de numero Indorum trägt («al Chwarizmi über die indische Zahlschrift»).
Im heutigen digitalen Zeitalter sind Algorithmen unverzichtbar, um Erkenntnisse aus den immensen Datensätzen zu gewinnen. Algorithmen müssen in maschinell bearbeitbarer Programmiersprache formuliert werden, damit ein Computer die Rechenoperationen anwenden kann.
b) Abgestufte Fähigkeiten von Algorithmen
Algorithmen zur Entscheidunterstützung (decision-support algorithms) helfen bei einer Entscheidung, ohne jedoch den Entscheid selbst auszuführen. Die folgenden drei Stufen von Finesse des Analyseresultats lassen sich unterscheiden:
- Deskriptive Algorithmen beschreiben bisher unbekannte Beziehungen innerhalb von gegenwarts- und vergangenheitsbezogenen Datensätzen. Beispielsweise kann die Arbeitgeberin durch den Vergleich von Gehaltsabrechnungs-Informationen und Arbeitsleistung feststellen, wie die Dauer der Ferien die Produktivität in den umliegenden Arbeitswochen beeinflusst.
- (2) Prädiktive Analytik dient dazu, die Wahrscheinlichkeit künftiger Ereignisse oder Ausgänge anhand bestimmter Indikatoren und statistischer Regelmässigkeiten in den Datensätzen vorherzusagen.
- (3) Präskriptive Algorithmen versorgen den Anwender mit Handlungsempfehlungen zur Erreichung seiner Ziele.
Entscheidfällende Algorithmen (decision-making algorithms) generieren eine Entscheidung oder führen eine Massnahme gegenüber einem sozialen oder physikalischen System aus. Beispielsweise kann ein entscheidfällender Algorithmus eine Person von internationalen Flugreisen direkt ausschliessen.
c) Künstliche Intelligenz
Die Geburtsstunde der Forschung nach KI wird auf eine Konferenz von 1956 datiert, die der Computerwissenschaftler John McCarthy am Dartmouth College (New Hampshire, USA) organisiert hat. KI-Systeme sind Software- und gegebenenfalls auch Hardware-Systeme, die ihre Umwelt über Sensoren wahrnehmen. Darauf interpretieren sie die Daten in algorithmischen Rechenoperationen und bestimmen zur Erreichung des vorgegebenen Ziels die besten Massnahmen, die sie in der physischen oder digitalen Dimension umsetzen. KI-Systeme können ihr Verhalten anpassen, wenn sie spüren, dass sich die Umwelt durch ihre Handlungen verändert. Zur KI gehört der Versuch, die neuronale Struktur des menschlichen Gehirns mit den Mitteln der Informatik nachzubauen. Die einzelnen Schritte in Vorgängen wie Lernen, Kreativität und Aufgabenerledigung mit «gesundem Menschenverstand» sollen in mathematische Modelle übersetzt werden, sodass Maschinen sie replizieren können. Trotz dieser Kennzeichen fehlt jedoch eine klare Begriffsdefinition von KI.
Es wird zwischen schwacher (weak oder narrow) und starker (strong oder general) KI unterschieden. Die gegenwärtigen Anwendungen von KI gehören zu ersterer Kategorie; sie können beispielsweise ein Spiel gewinnen, eine Stimme erkennen oder auf Muster in einem Computertomografie-(CT-)Scan hinweisen. Starke KI hingegen beschreibt Maschinen von höherer Intellektualität, einer Eigenwahrnehmung und Selbstkontrolle, sodass sie irgendein Problem in beliebigem Kontext lösen können. Selbst Probleme, die im Zeitpunkt der Schaffung der KI noch nicht existierten, kann starke KI erledigen.
Maschinelles Lernen ist die hauptsächliche Form der (gegenwärtig noch schwachen) KI. Den Begriff des maschinellen Lernens prägte im Jahr 1959 der IBM-Ingenieur Arthur Samuel, der seinerseits an John McCarthys KI-Konferenz teilgenommen hatte. Unter dem Sammelbegriff des maschinellen Lernens existieren verschiedene Technologien. Allgemein geht es darum, ein Computerprogramm daraufhin zu trainieren, in einem Datensatz selbständig Muster zu erkennen, ohne zu verstehen, was die Muster bedeuten. Der Clou am maschinellen Lernen ist die Fähigkeit, zu generalisieren: Muster werden nachher auch in Daten erkannt, die nicht Teil der Trainingsdaten bildeten. Hierdurch hebt sich das maschinelle Lernen von sog. Expertensystemen ab, die über Wissen in Form von im Voraus abgespeicherten «wenn-dann»-Regeln verfügen. Von (starker) KI unterscheiden sich Systeme des maschinellen Lernens dadurch, dass sie nicht autonom handeln, sich nicht an Veränderungen anpassen und sich keine eigenen Ziele stecken.
d) Korrelationen und Kausalitäten
Algorithmen gewinnen Erkenntnisse nach heutigem Stand der Technik hauptsächlich durch das Aufdecken von Korrelationen in Datensätzen. Eine Korrelation (von lat. cum relatione: «mit Wiederholung», und mittellat. correlatio: «Wechselbeziehung») beschreibt eine statistische Beziehung zwischen zwei Variablen A und B, ohne den Grund für die Beziehung – welcher in einer Kausalität oder einem Zufall bestehen kann – zu nennen. Es handelt sich somit um eine rein deskriptive Erkenntnis, die weitgehend von einem Verstehensprozess losgelöst ist und jeglicher individuell nachvollziehbaren Begründungsleistung entbehrt. Eine Korrelation vermittelt ein vergleichsweise oberflächliches Wissen, weil sie nicht Licht ins Innere einer Variablen bringt. Stattdessen identifiziert sie eine andere nützliche, sog. stellvertretende oder Proxy-Variable: Wenn die gesuchte Variable A mit dem Stellvertreter B korreliert, genügt es, nach B Ausschau zu halten, um vorherzusagen, was höchstwahrscheinlich mit A passieren wird. Als Beispiel für eine arbeitsplatzbezogene Korrelation (die sich jedoch als falsch herausgestellt hat) mag diejenige zwischen Lohn und Lebensglück dienen: Ökonomen und Politikwissenschaftler glaubten über Jahre, dass ein Einkommensanstieg zu mehr Zufriedenheit führe. Diese Annahme stimmt jedoch nur für Einkommen bis zu einer bestimmten Schwelle; ein Lohnanstieg darüber hinaus verbessert die Glücksgefühle kaum mehr.
Eine Kausalität ist die Beziehung zwischen Ursache und Wirkung (von lat. causalis: «die Ursache angebend», und mittellat. causalitas: «Ursächlichkeit»). Im Gegensatz zur Korrelation wird hier der Grund, warum aus Ursache A die Wirkung B folgt, erklärt.
Menschen haben beim Anblick einer Korrelation einen «intuitiven Hang dazu, eine kausale Beziehung zu sehen, obschon es keine gibt». Tatsächlich bestehen zwischen Korrelation und Kausalität Gemeinsamkeiten. Eine Korrelation kann ein Indiz für einen möglichen Kausalzusammenhang darstellen. Der Wahrheitsgehalt einer Kausalität kann, ähnlich wie bei einer Korrelation, selten bewiesen werden; es kann bloss festgestellt werden, dass er mit einem hohen Grad an Wahrscheinlichkeit vorliegen muss. Die Philosophie versucht, die Ursächlichkeit mithilfe der Wahrscheinlichkeitssteigerung zu definieren: A verursacht B kausal, wenn A die Wahrscheinlichkeit von B erhöht. Beispielsweise mag Einigkeit darüber bestehen, dass Uber-Chauffeure, die rücksichtslos fahren, Unfälle provozieren, obwohl dieses Vorzeichen bloss dazu neigt, eine Kollision wahrscheinlicher, nicht absolut sicher zu machen.
Richtigerweise sind Korrelation und Kausalität aber bewusst auseinanderzuhalten. Die Wahrscheinlichkeiten einer Korrelation beziehen sich auf eine statische Welt. Kausalität erklärt dagegen, wie sich die Wahrscheinlichkeiten ändern, wenn sich die Welt um die Variablen A und B herum wandelt. In der dynamischen Welt, in der wir leben, müssen Korrelationen somit ein Ablaufdatum tragen; ihr Wert ist zeitlich limitiert. Demgegenüber bewahren Kausalitäten Beständigkeit. Es handelt sich um autonome «Eltern-Kind-Beziehungen» zwischen Variablen. Wenn sich Umweltbedingungen ändern, beeinflusst dies in der Regel nur einige wenige kausale Beziehungen, während die übrigen stabil bleiben.
Die Frage steht im Raum, wann sich welche Methode besser für die Wissensgewinnung eignet. Bei gewissen Autoren geniesst die Kausalität generell einen höheren Stellenwert als die Korrelation, weil sie beständig ist und direkten Einblick in die innere Beziehung zwischen Ursache und Wirkung gewährt. Demokrit von Abdera (460/459–370 v.Chr.) wäre es eigener Aussage zufolge lieber gewesen, eine einzige Ursachenerklärung zu finden als König von Persien zu werden. Es wird kritisiert, dass die Wissenschaft auf dramatische Art ihre Identität opfere, wenn sie nicht mehr nach Ursache und Wirkung suche. Zudem können sich nicht begründbare Entscheidungen auf die Wirklichkeit auswirken: Beispielsweise erscheint das Handeln desjenigen Algorithmus uninformiert, der Arbeitnehmer aus entfernten Wohnorten nicht zur Beförderung vorschlägt, weil eine Korrelation zwischen langem Arbeitsweg und kurzer Verweildauer im Unternehmen besteht. Die Weglänge ist jedoch möglicherweise nicht kausal für den Jobwechsel, sondern der Stress aufgrund überfüllter Verkehrsmittel. Wären die Arbeitszeiten flexibel, könnte der Angestellte einen weniger dicht besetzten Zug nehmen und bliebe der Stelle länger treu. Arbeitnehmer mit langem Arbeitsweg hätten plötzlich eine Chance, befördert zu werden.
Korrelationen sollten jedoch nicht als unnütz abgetan werden. In Rechnung zu ziehen ist, dass die Digitalisierung zu einer regelrechten Schwemme an Daten führt. Dies spielt der Wissensgewinnung durch Korrelationen in die Karten: «Correlations are useful in a small-data world, but in the context of big data they really shine.» Korrelationsanalysen sind schneller und billiger als das Suchennach Kausalitäten in grossen Datensätzen. Für viele Fragen genügt es, bloss zu wissen, dass sich zwei Variablen dauerhaft auf eine bestimmte Weise verhalten, ohne dass es nötig wäre, zu verstehen, warum dies so ist. MAYER-SCHÖNBERGER und CUKIER mutmassen sogar, dass Kausalität künftig nicht mehr die primäre Quelle der Wissensgewinnung sein werde.
Nach vorliegend vertretener Ansicht tragen Kausalitäten und Korrelationen komplementär zum Weltverständnis bei. Korrelationen sind umso zuverlässiger, je grösser die Datenmenge ist. Hierin liegt ein grosses Potenzial im Vergleich zum menschlichen Denken, droht doch dem Gehirn bei grossen Mengen an Informationen die Überforderung. Allerdings sind Algorithmen nach dem Stand der Technik noch nicht imstande, kausale Beziehungen zwischen Daten zu verstehen. Sie können die entdeckten Korrelationen nicht auf ihre Ursächlichkeit hin anzweifeln in der Art: «Dieses Resultat macht keinen Sinn; ich werde es nochmals ausrechnen.» Daher ist menschliches, kausales Denken nach wie vor zur Überprüfung der Stichhaltigkeit einer Korrelation erforderlich.
2.2.5 Big Data
a) Fehlende Legaldefinition
Das Phänomen «Big Data» ist relativ jung. Es gibt keine Legaldefinition des Begriffs, und er erscheint weder im DSG noch in der DSGVO. Auf Englisch kommt «Big Data» deutlich häufiger vor als in jeder deutschen Übersetzungsvariante. Sowohl in der Einzahl als auch in der Mehrzahl ist «Big Data» anzutreffen. Vorliegend wird der Singular bevorzugt, weil die Daten erst als Masse wertvoll werden und sich rechtliche Überlegungen auf das Phänomen als Ganzes beziehen.
b) Die (mindestens) drei V-Eigenschaften
Die Versuche der Literatur, «Big Data» zu definieren, beginnen häufig mit den drei V-Eigenschaften (volume, variety, velocity), die, soweit ersichtlich, erstmals LANEY (2001) beschrieben hat. Big Data beschreibt demnach Datenbestände, die aufgrund ihres Umfangs (volume), ihrer Unterschiedlichkeit (variety) oder ihrer Schnelllebigkeit (velocity) nur begrenzt mit herkömmlichen Tools bearbeitet werden können.
Wie aus dem Begriff «Big» Data erhellt, ist das Datenvolumen (volume) im Grundsatz unbegrenzt. Im Jahr 2021 werden in jeder Stunde mehr Daten aufgezeichnet werden als in den letzten 30’000 Jahren. Das Wachstum ist exponentiell. Das Bundesgericht führt das Stichwort Big Data, soweit ersichtlich, nur in einem einzigen Entscheid aus dem Jahr 2014 explizit auf: Dort bezeichnen die Beschwerdeführerin und die Vorinstanz den Sachverhalt als «Big Data-Fall», d.h. als Fall «mit einer immensen Datenmenge». Streitgegenstand sind unter anderem «ein Datenvolumen von 22 Gigabytes bzw. 89’000 Dateien in 11’000 Verzeichnissen» sowie «65’345 Dateien in 346 Unterverzeichnissen» und «521’721 Wörter, die ausgedruckt 1’449 A4-Seiten» füllen. Das Bundesgericht widerspricht dieser Beschreibung von Big Data nicht. Doch «big» im Gegensatz zu «small» in absoluten Zahlen auszudrücken, ist schwierig, da das Verständnis der Grösse von Unternehmen zu Unternehmen relativ ist und sich über die Zeit ändern kann. Die Zahlen im zitierten Bundesgerichtsentscheid erscheinen dem Autor ob der immer intensiveren Datenaufzeichnungen an Büroarbeitsplätzen als gering.
Mit der Vielfalt der Daten (variety) ist gemeint, dass die Art der Daten (strukturiert und unstrukturiert; Inhalte und Metadaten) und ihre Herkunft (unternehmensintern oder aus dem Internet) irrelevant und im Grundsatz unbegrenzt sind. Die Arbeitgeberin kann bisher nicht aufeinander bezogene Daten, beispielsweise traditionelle und nichttraditionelle Arbeitnehmerdaten, zusammenführen. Zu Ersteren zählen die Angaben im Lebenslauf über frühere Berufserfahrung und Ausbildungen. Letztere sind in der Regel nicht in der Datenbank der Personalabteilung gespeichert und betreffen etwa Daten der produzierenden oder der Finanzabteilung, aber auch der öffentlichen Register, Daten über Aktivitäten in sozialen Netzwerken, Sensordaten, Kommunikations-Metadaten oder den Browserverlauf. Durch die Kombination entstehen Ergebnisse von neuer Qualität.
Die Daten liegen nicht einfach auf Speicherplatten herum: «Alles fliesst» (altgr. πάντα ῥεῖ, «pánta rhei», Heraklit von Ephesos um 520–460 v.Chr.). Big Data zieht als schnelllebiger, «reissender Strom» vorbei (velocity). Der weltweite Internet-daten-Verkehr hat sich in den fünf Jahren zwischen 2006 und 2011 verzwölffacht. Die Datenerfassung und -analyse erfolgen in Echtzeit, um Massnahmen mit unmittelbarer Auswirkung auf das Leben von Personen zu treffen. Dazu braucht es spezielle Analyse-Algorithmen und hochleistungsfähige Hardware.
Teilweise führt die Literatur weitere V-Eigenschaften auf, die über die drei von LANEY erwähnten hinausgehen: DE MAURO, GRECO und GRIMALDI folgern aus einer systematischen Literaturanalyse, dass Big Data einen Wertschöpfungsprozess einschliesse (sozusagen als viertes V: value). Für Big Data ist somit essenziell, dass in der dritten Phase des Daten-Lebenszyklus die in Daten steckende Wertchance genutzt wird. Um den Unterschied zwischen den Daten als Rohstoff und dem Wertschöpfungsprozess hervorzuheben, tritt mancherorts der Zusatz «Analytik» hinzu («Big Data-Analytik» bzw. «big data analytics»).
Um die V-Reihe um ein fünftes Glied zu erweitern, sei vorliegend auch die Richtigkeit der Daten (veracity) angesprochen. Sie lässt sich aufgrund des Volumens von Big Data, der Entstehungsgeschwindigkeit und Vielfalt kaum überprüfen, jedoch sollen die Ungenauigkeiten dank der grossen Datenmenge und geeigneter Analysewerkzeuge vergleichsweise gut auszumerzen sein.
c) Kritik am Begriff «Big Data»
Die Verwendung des Begriffs «Big Data» stösst teilweise auf Kritik. Diese zielt auf den ersten Wortteil, «Big». Vergessen gehe dabei, dass auch gestützt auf kleine Datensätze wichtige Entscheide gefällt würden. Ausserdem sei die Vielfalt der Daten wesentlich prägender als das Volumen und biete insbesondere im Bereich der Personalverwaltung mehr Innovationspotenzial. Auch der Aspekt der Geschwindigkeit, das dritte V, dürfte im statischen Ausdruck «Big» zu kurz kommen. Vermehrt taucht daher der Begriff «Smart Data» auf, der die Wissensgewinnung ins Zentrum rückt.
d) Verhältnis zu People Analytics
An gewissen Stellen wird People Analytics als ein Teilbereich von Big Data beschrieben, in welchem es um Big Data-Analysen geht, die auf den Arbeitsplatz bezogen sind. Richtigerweise ist jedoch zu differenzieren: People Analytics funktioniert mit oder ohne Big Data. Ist die Datenmenge klein, aber sind andere beschriebene Aspekte erfüllt, insbesondere der Einsatz von Algorithmen, so handelt es sich ebenfalls um People Analytics. Beispielsweise kann es sowohl für ein Gross- als auch für ein Kleinunternehmen sinnvoll sein, die E-Mail-Prozesse zu optimieren. Bei wenigen Angestellten wird die Datenmenge jedoch kleiner bleiben.
2.2.6 Zwischenfazit: zusammenhängende technische Konzepte
Hinter dem Wort «Analytics» steckt ein Daten-Lebenszyklus. Der Daten-Lebenszyklus besteht aus den vier Phasen der Beschaffung, Analyse, Nutzung und Löschung oder Wiederverwertung der Daten. Betreffend die erste Phase – Beschaffung – wurden sowohl der Begriff des Datums als auch die Hardware und Infrastruktur zur Aufzeichnung der Daten beschrieben. In der zweiten Phase – Analyse – kommen Algorithmen zum Einsatz, die gegenwärtig noch relativ einfältig nach Korrelationen suchen, aber durch KI immer intelligenter werden. In der dritten Phase – Nutzung – zeigt sich, dass die Big Data-Wirtschaft ein Wertschöpfungsprozess und kein Selbstzweck ist. Kommt es in der vierten Phase zu einer Wiederverwendung, erlangen alle diese Begriffe erneut Relevanz.
Rechtlich und für die vorliegende Forschungsfrage relevant ist das Gesamtbild: Hinter People Analytics steckt eine enorme technische Apparatur. Es wächst eine datafizierte Welt heran, in der immer und überall Datenerhebungen und -analysen geschehen können und in der sich der Arbeitnehmer zurechtfinden muss. In dieser Welt hängen Begriffe wie «Sensoren», «Algorithmen» und «Big Data» zusammen. Sie bedingen und stimulieren sich gegenseitig in Wechselwirkung: Daten, Computerinfrastruktur und Algorithmen sind Voraussetzungen für eine Big Data-Wirtschaft; umgekehrt wird der gewonnene Mehrwert Investitionen in die Erhebung weiterer Daten mit verbesserter Hardware, höherer KI und erweiterter Zwecksetzung ermöglichen. Die konkreten wirtschaftlichen Verwendungszwecke von People Analytics werden sogleich dargestellt.
2.3 Verwendungszwecke
2.3.1 Arbeitnehmer-Lebenszyklus
Nachdem der Wortteil «Analytics» und der Daten-Lebenszyklus vorgestellt worden sind, soll nun der erste Wortteil – «People» – in den Vordergrund rücken. Es ist zu erklären, inwiefern die Menschen von dem Phänomen betroffen sind und wie sich die Interaktion zwischen Mensch und Technik gestaltet. Darzustellen sind die Verwendungszwecke von People Analytics. Die Wissensgewinnung durch Datenanalysen ist kein Selbstzweck, sondern das Ziel ist stets, das gewonnene Wissen auf die Wirklichkeit anzuwenden. Der Nutzen von People Analytics besteht beispielsweise darin, Schulungsressourcen bei den richtigen Gruppen von Arbeitnehmern zu allozieren oder sich von Praktiken oder Personen zu trennen, die hohe Kosten verursachen.
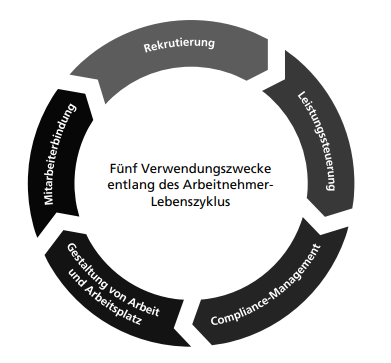
Die Zwecke von People Analytics können entlang des Lebenszyklus eines Arbeitnehmers in eine zeitliche Ordnung gesetzt werden: Arbeitnehmende begegnen Datenbearbeitungen erstmals in der Bewerbungsphase, später während der gesamten Dauer des Arbeitsvertrags und auch nach dessen Beendigung. Orientiert am Arbeitnehmer-Lebenszyklus können die mit Personalanalysen verfolgten Zwecke grob in fünf Kategorien unterteilt werden: Rekrutierung, Leistungssteuerung, Compliance-Management, Gestaltung von Arbeit und Arbeitsplatz sowie Mitarbeiterbindung (siehe Abb. 4)
2.3.2 Rekrutierung
In der Bewerbungsphase müssen die eingehenden Kandidatenprofile mit der Stellenbeschreibung abgeglichen (matching) und der Wunschkandidat (der perfect match) herausgefiltert werden (shortlisting). So gleicht beispielsweise dieFunktion Talent Match von LinkedIn die von Unternehmen gesuchten Profile in Echtzeit mit den Profilen der Netzwerk-Mitglieder ab. Watson von IBM eruiert, welches Profil voraussichtlich die höchste persönliche Arbeitnehmerleistung erbringen wird. Die Software Kenexa prognostiziert die Verweildauer im Unternehmen und die Eignung für eine Führungsposition. Auf eine längerfristige Bindung von Arbeitnehmenden will das Analytik-Unternehmen Evolv (heute Cornerstone OnDemand) aus der Aktivität in einem sozialen Netzwerk wie Facebook, einer kurzen Distanz zwischen Wohn- und Arbeitsort sowie einer kreativen Persönlichkeit schliessen – nicht entscheidend seien Berufserfahrung und Ausbildung. Zudem verzeichnen Bewerber, die eine eigene Internet-Suchmaschine installiert haben, 15 Prozent weniger Fehltage und erzielen eine höhere Kundenzufriedenheit als solche, die einen vorinstallierten Browser benützen.
In Zeiten des Fachkräftemangels ist es nicht immer eine Option, sich mit den passiv empfangenen Bewerbungen zu begnügen. Stattdessen ermittelt die Arbeitgeberin – mit Firmen wie Entelo, Talentwunder oder Joberate im Rücken – aus Webdaten und aktuellem Userverhalten aktiv, ob Kandidaten latent bereit wären, für eine neue Stelle die bestehende zu kündigen und umzuziehen (active sourcing). Anzeichen für eine Wechselbereitschaft bestehen, wenn eine Person nach längerer Zeit ihr Profil in den sozialen Netzwerken auf den neusten Stand bringt, oder je nachdem, welche ihr zugesandten Inhalte sie liest und welche nicht. Auf die Personensuche spezialisierte Suchmaschinen erleichtern das Finden von Informationen über Individuen.
Ist eine engere Auswahl von passenden Profilen getroffen worden, kann der Algorithmus direkt das Bewerbungsgespräch führen. Das Kosmetikunternehmen L’Oréal verwendet einen Chatbot mit Namen Mya, der Fragen stellen und beantworten sowie Qualifikationen, Wohnort und Gehalt überprüfen kann. Geplant ist aber auch die Berücksichtigung weicher Faktoren, etwa ob der Bewerber zu den Unternehmenswerten von L’Oréal passt. Weitergehende Lösungen messen physiologische Reaktionen und passive Verhaltenscharakteristika wie Herzschlag, Augenbewegungen und Gesichtsausdruck eines Bewerbers während seiner Vorstellung.
Eine strategische Personalplanung ermöglichen das Schweizer Unternehmen People Analytix oder die Software Jobfeed von Textkernel, indem sie vorhersagen, wie sich der Personalmarkt entwickeln wird. IBM-Analysten erfassen zur Bestimmung des künftigen unternehmensinternen Fachkräftebedarfs die Fähigkeiten und Erfahrungen der gesamten IBM-Belegschaft. Der amerikanische Lebensmittelfabrikant Conagra Foods sah sich mit dem Problem konfrontiert, dass über die Hälfte seiner Angestellten in den nächsten zehn Jahren in Pension gehen wird, weshalb er neues Personal brauchte, das fähig und willens war, schnell neue Aufgaben zu lernen. Eine Datenanalyse ergab, dass diese Fähigkeit über alle Altersklassen verteilt war und Conagra Foods bei der Rekrutierung nicht nur auf junge Leute beschränkt war. Mit People Analytics kann die Arbeitgeberin somit Lücken im Unternehmenswissen schliessen bzw. ihr Nichtwissen bewirtschaften, was genauso wichtig ist wie die Kultivierung des Wissens.
2.3.3 Leistungssteuerung
Zunächst ist im Rahmen der Leistungssteuerung an die elektronische Überwachung (electronic surveillance) zu denken im Hinblick darauf, ob der Mitarbeiter seine arbeitsvertraglich geschuldete Leistung überhaupt erbringt. Besonders wenn die Arbeitgeberin das Arbeiten von zu Hause aus zulässt, wird die Leistungsüberprüfung schwieriger. Das Zeiterfassungssystem Work Diary von Upwork zählt deshalb die Tastenanschläge im Homeoffice, erstellt alle zehn Minuten eine Bildschirmfotografie und enthält einen Sofortnachrichtendienst, um den Arbeitnehmer zu kontaktieren. Im Einsatz sind auch Softwares, die über eine Webcam alle zehn Minuten eine Foto des Mitarbeiters persönlich im Homeoffice erstellen und den E-Mail-Verlauf und die Kalendereinträge kontrollieren.
Der US-Postzulieferer FedEx setzt in seinen Logistikzentren auf einen Paketscanner, den der Arbeitnehmer am rechten Unterarm trägt. Der Scanner erfasst die Pakete und zeichnet dabei die Arbeitsgeschwindigkeit auf. Ein Countdown gewährt dem Arbeitnehmer eine bestimmte Anzahl Sekunden bis zum Scannen des nächsten Pakets. Gerät der Arbeitnehmer in Verzug, weil er beispielsweise in einen falschen Korridor im Lager eingebogen ist, ergeht eine Benachrichtigung an eine Aufsichtsperson. Der Detailhändler Tesco senkt mit vergleichbaren Geräten seinen Bedarf an Vollzeitstellen in den Warenhäusern um 18 Prozent. Amazon arbeitet mit einem Ultraschall-Armband, das vibriert, wenn der Arbeitnehmer die falsche Ware verpackt. Intelligente Arbeitshandschuhe dokumentieren die Arbeitsschritte, indem sie Informationen von Maschinen, die der Arbeitnehmer bedient, lesen.
Das Elektroenzephalografie-Stirnband (EEG headband) mit Namen «Muse» misst die Gehirnwellen des Angestellten und damit seine aktuelle Leistungsfähigkeit und Aufmerksamkeit bzw. seinen Müdigkeitsgrad und schlägt ihm gegebenenfalls eine Pause vor. Intelligente Brillen (smart eyeglasses) mit eingebauten Kameras zur Blickverfolgung (eye tracking) registrieren nicht nur, was der Angestellte sieht, sondern auch, ob er darauf fokussiert oder abgelenkt ist. Das Unternehmen Schlumberger, ein Dienstleister für Erdölfelder, gewährt seinen Angestellten häufigere kurze Pausen, weil eine systematische Videoanalyse ergeben hat, dass so die Produktivität steigt.
Zur Auswertung von Kundengesprächen überprüfen Callcenter mit einer Stichwortsuche (keyword spotting), wie oft der Agent das zu verkaufende Produkt oder das Preis-Leistungs-Verhältnis erwähnt, und mit einer Stimmanalyse, ob Mitarbeiter (oder Kunden) zu langsam sprechen und welche Emotionen mitschwingen. Diese in Telefonzentralen heimische Technologie verlässt nun ihr Stammgebiet: Auch bei Hostessen, Kellnern und Verkäuferinnen in Supermärkten wird gemessen, wie oft sie ihren Kunden ein Lächeln schenken. Laut dem Unternehmen Affectiva aus Boston, das Emotionsmesstechnik produziert und Gesichtsausdrücke scannt, neigen Frauen in alltäglichen Gesprächen dazu, häufiger zu lächeln als Männer.
Das Telematik-System On-Road Integrated Optimization and Navigation (ORION) des Postzulieferers UPS optimiert die Bewegungsmuster von Postboten anhand ihrer Geolokalisationsdaten: ORION berechnet die kürzeste und hinsichtlich Benzinverbrauch billigste Fahrstrecke, lenkt die Autos an Staus und schlechtem Wetter vorbei und ermöglicht personalisierte Lieferungen (z.B. in Bezug auf die Lieferzeit). Solche Flottenanalyse-Systeme kommen auch im Flugverkehr vor. Möglich ist darüber hinaus die Verfolgung der Position und der Bewegungen der Mitarbeiter persönlich durch Computerchips, die in die Arbeitskleidung eingenäht sind: Ein Spital in Florida hat die Heilmittelvorräte besser auf die Krankenstationen verteilt, nachdem es realisiert hatte, wie viel Zeit die Krankenschwestern damit verloren, zusätzliche Medikamente aufzuspüren. Das Medizinalunternehmen Propeller Health (zuvor Asthmapolis) deckt Umweltauslöser für Asthmaanfälle der Arbeitnehmer auf (z.B. die Aufenthaltsnähe zu bestimmten Pflanzenkulturen), indem es Ortungsdaten aus einem GPS-Sensor und Atmungsdaten aus einem Asthma-Inhalator zusammenführt.
Gesundheitsprogramme (wellness programmes) sind Datenbearbeitungen zur Bekämpfung von Übergewicht, Rauchen, hohem Blutdruck und weiteren physischen Beschwerden. Der Detailhändler Walmart identifiziert Arbeitnehmer mit erhöhtem Diabetesrisiko und legt ihnen nahe, einen Arzt aufzusuchen oder sich einem Programm gegen Fettleibigkeit und für gesunde Ernährung zu unterziehen. Mitarbeiterinnen, die auf der Walmart-Gesundheits-App Arztrezepte zur Empfängnisverhütung nicht mehr einlösen und nach Themen über Fruchtbarkeit suchen, erhalten Informationen zur Schwangerschaftsvorsorge und Kontakte zu Hebammen. Mit besseren Gesundheitswerten steigt die Leistungsfähigkeit der Arbeitnehmer. Zusätzliche Profite locken in den USA, wo sich die Arbeitgeberin oft an den Krankenversicherungskosten der Arbeitnehmer beteiligt: Die Arbeitnehmer, die sich immer besserer Gesundheit erfreuen, stellen seltener Versicherungsfälle in Rechnung, wodurch Prämienverbilligungen möglich werden.
Den Vermittlungsplattformen ist die jederzeitige Aufrechterhaltung ihres Systems für die Kunden wichtig. Der Essenszulieferer Deliveroo aus London beispielsweise wertet aus, wie lange seine Kuriere benötigen, um eine Bestellung zu bestätigen, und ob sie Bestellungen ablehnen. Erreicht der Kurier die vereinbarte Leistung nicht, blockiert ihn das System. Im gleichen Stil operiert der Taxivermittler Uber: Hat sich ein Taxichauffeur ins System eingeloggt, muss er Aufträge innert zwanzig Sekunden akzeptieren. Verpasst er drei Gelegenheiten in Folge, wird er automatisch für einige Minuten ausgeloggt. Im Wiederholungsfall wird sein Konto gelöscht.
Einen alternativen Ansatz verfolgt Microsoft mit dem Programm MyAnalytics. Es geht hier darum, den Mitarbeitern die Mittel zu verschaffen, um sie zu höherer Leistung basierend auf Selbständigkeit zu befähigen (empowering employees). Ein personalisiertes Übersichtsfenster (Dashboard) zeigt dem Arbeitnehmer einen wöchentlichen E-Mail-Zusammenschnitt an und, zum Ansporn, die Durchschnittswerte des Unternehmens betreffend E-Mail-Erledigung. Nur die Arbeitnehmer selbst können ihre personenbezogenen Daten einsehen.
2.3.4 Compliance-Management
«Compliance» bedeutet wörtlich die «Befolgung» und bezieht sich auf alle für ein Unternehmen verbindlichen Normen. Die Arbeitgeberin haftet für die Nichtbefolgung durch ihre Angestellten.
Dem Vermögensschutz der Arbeitgeberin dienen Videoüberwachungsanlagen und die Aufzeichnung der Tastenanschläge bei der Kasse. Ein japanischer Antidiebstahlsitz kontrolliert, ob der berechtigte Fahrer, dessen individueller Abdruck über 360 eingebaute Drucksensoren ertastet wird, im Firmenauto Platz nimmt. Die Geschäftsgeheimnisse schützt das System Teramind, das bei der Bank BNP Paribas und dem Mobilfunknetzbetreiber Salt (vormals Orange) im Einsatz ist: Es filtert alle E-Mails einschliesslich Anhängen und Bildern sowie äusseren Verbindungsdaten (Randdaten) beispielsweise auf Namen von Konkurrenten (sog. Datenscreening) und warnt die Arbeitgeberin, wenn Angestellte vertrauliche Dokumente teilen. Der Lügendetektor des Schweizer Beratungsunternehmens 1-prozent GmbH entlarvt Hochstapler dadurch, dass sie in ihre unwahren Aussagen immer gerade so viel Wahrheit einflechten, dass ihr Gegenüber unablässig verwirrt wird. Ein britisches Pendant deutet die unbewusste Unsicherheit in einer Stimme als Zeichen möglicher betrügerischer Absichten.
Die US-Investmentbank JP Morgan verwendet das Datenscreening zur Aufdeckung von Verstössen gegen finanzmarktrechtliche Verhaltenspflichten wie beispielsweise Betrug (fraud detection) oder Insider-Handel.
Zur Kontrolle von Berechtigungen sind biometrische Zutritts- oder Kassensysteme, bei denen die Mitarbeitenden sich mit ihrem Fingerabdruck identifizieren müssen, weit verbreitet, so etwa in der Gastronomie.
Auf die Einhaltung von Arbeitssicherheits-Richtlinien zielen die intelligenten Teppiche der Lausanner Firma Technis, die registrieren, wer wo hintritt. Andernorts warnen smarte Socken den Arbeitnehmer vor Stürzen. Die Software Intelligent Edge von Microsoft ermittelt via Videokameras, ob ein Mitarbeiter die Schutzbrille nicht aufsetzt oder ein Fass mit einer gefährlichen Chemikalie ausleert. Arbeitsschuhe mit einem integrierten Drucksensor vibrieren, wenn der Mitarbeiter übermässig schwere Lasten trägt. Drohnen überwachen die Sicherheit von Geleisearbeitern der Bahn. Lastwagenfahrer tragen intelligente Mützen, die sie vor einem Sekundenschlaf warnen. Uber misst den Radeinschlag, um die Fahrfähigkeit und den Fahrstil seiner Taxichauffeure zu kontrollieren.
Um die Compliance mit Antidiskriminierungs-Bestimmungen zu gewährleisten, prüft das System Themis, ob Softwares Vorurteile und Verzerrungen enthalten. Auch die Software von Paradigm aus San Francisco unterstützt Organisationen in ihrem Bestreben, vielfältiger und integrativer zu werden. Diese Software enthält Befangenheitstests, um Vorurteile, die jeder im Laufe seines Lebens entwickelt, aufzudecken.
Die Datenanalysen dienen ferner als Grundlage, um die Interessen- und Werteangleichung zwischen Unternehmen und allen Mitarbeitenden voranzutreiben.
2.3.5 Arbeits- und Arbeitsplatzgestaltung
Zwischen Daumen und Zeigefinger implantierte Mikrochips vereinfachen die Arbeitsabläufe und erhöhen die Bequemlichkeit. Mit einer Handbewegung lassen sich Türen öffnen, Computer starten, Automotoren anwerfen oder Kantinenrechnungen bezahlen. Rund hundert Angestellte der amerikanischen Technologieunternehmung Three Square Market liessen sich 2018 chippen.
Angestellte der Universität Luzern und der britischen Zeitung Daily Telegraph finden unter ihrem Arbeitstisch ein Infrarotkästchen, das die Auslastung der Arbeitsplätze misst. Dies dient der Gebäudeplanung.
Die Software zur Personal- und Rollmaterial-Einsatzplanung (Sopre) der Schweizerischen Bundesbahnen (SBB) bereitet täglich die Dienste von 20’000 Lokomotivführern, verteilt auf mehrere tausend Züge, vor. Bei IBM stellt eine Software die Arbeitsteams zusammen, indem sie die für ein Projekt erforderlichen Qualifikationen mit den Lebensläufen der Arbeitnehmer abgleicht. Kurzfristige Ausfälle erkennt die Arbeitgeberin frühzeitig, wenn sie interne Daten mit externen verknüpft; beispielsweise erweist sich aus den Bewegungsprofilen in den betrieblichen Mobilfunkgeräten, wer sich in besonders stark grippegefährdeten Gebieten bewegt.
Kollaborationssoftwares (z.B. Microsoft Teams und Kaizala von Microsoft, Whatsapp Business von Facebook oder SAP) führen alle Kommunikationsdienste zusammen (unified communications), was den Austausch von Information erleichtert. Künftig soll die Kommunikation sogar direkt von Gehirn zu Gehirn laufen (mind-to-mind communication). Erforderlich sind hierfür ins Gehirn implantierteSpeicherkarten (brain chips). Bei einem Tierversuch wurden zwei Ratten solche Gehirn-Chips eingebaut. Die eine Ratte musste über Wochen anspruchsvolle Aufgaben erlernen, um an ihr Futter zu gelangen. Dieser Lernprozess wurde auf der Speicherkarte abgelegt. Danach wurde die Speicherkarte dieser Ratte über das Internet mit derjenigen der zweiten Ratte, die sich in einer entfernten Stadt befand, verbunden. Die zweite Ratte fand den Weg zum Futter auf Anhieb. Es ist somit technisch machbar, Lernprozesse und Wissen zwischen Arbeitnehmern auszutauschen. Die Literatur spricht diesbzgl. vom verbesserten «Robo Sapiens» (enhanced robo sapiens). Dieser ist Ausdruck des besprochenen Internets der (Dingeund der) Menschen.
Telepathie bestimmt auch die Interaktion zwischen Mensch und Roboter: Ein Arbeitnehmer kann über Handzeichen und Gehirnwellen den Industrieroboter Baxter des Massachusetts Institute of Technology (MIT) steuern und ihn beispielsweise veranlassen, eine Schraube anzuziehen. Andere Roboter werden am Körper getragen: Ein (weicher) anziehbarer Roboter (exosuit) des Harvard Biodesign Lab entlastet die Hüfte, was die Stoffwechsel-Kosten im Körper um 17,4 Prozent reduziert. Im Einsatz sind auch (harte) Exoskelette, mithilfe derer Arbeitnehmer auf Baustellen und in Werften schwere Gegenstände heben können.
Arbeitnehmer können virtuelle Büroassistenten, die Sprache verarbeiten (z.B. Siri von Apple, Alexa von Amazon, der Intelligent Agent von Adobe oder interne Webseiten), mit Informations-Recherchen beauftragen. Arbeitnehmer in der Automobilproduktion tragen die intelligente Brille Google Glass, bei der sie über einen verbundenen Touchscreen Hilfe für bestimmte Aufgaben anfordern können. Fahrzeuge zeigen den Mitarbeitern auf einem Bildschirm an, welche Werkstoffe sie für Produktionszwecke aus dem Lager entnehmen sollen (pick by light, weil Lichtpunkte das zu holende Material auf dem Display markieren).
2.3.6 Mitarbeiterbindung
Um Angestellte beruflich zu fördern, ermitteln intelligente Tutorensysteme, unter welchen Bedingungen sich die Talente (high potentials) bestmöglich entfalten. Google und McDonalds entwickeln gestützt auf die Analyse der Mitarbeiterbefragungen spezielle Trainingsprogramme für Vorgesetzte. Ein virtueller Karriereassistent (Virtual Career Assistant, Vicas) errechnet für jeden Mitarbeiter des Versicherungsunternehmens Axa das individuelle Risiko, dass ein Roboter seine Arbeit übernehmen könnte. Als Lösung zeigt der Vicas Möglichkeiten der internen Stellenmobilität und Weiterbildung an, damit die Betroffenen nicht auf ihren (gefährdeten) Positionen verharren. Ein Konkurrenzprodukt hierzu ist der Professional Reputation Score von Reputation.com, der den beruflichen Status bewertet und darauf den nächsten Karriereschritt vorschlägt.
Es lässt sich ein innerbetrieblicher sozialer Graph (enterprise social graph) errechnen, wenn man die Kommunikationsflüsse im Unternehmen nachzeichnet. Microsoft und IBM testen auf diese Weise den Zusammenhalt auf Individual-, Team- und Unternehmensebene und definieren so beispielsweise, über wen am meisten Informationen laufen, wer andere beeinflusst und wer isoliert ist. Die Bank of America und Cubist Pharmaceuticals setzen auf die Mitarbeiterausweise von Humanyze, die mit Mikrofon, Infrarot-Empfänger, Schrittzähler und Blue-tooth-Sender ausgestattet sind. Daraus erhellen die räumliche Position der Arbeitnehmer zueinander und ihre mündliche Kommunikation untereinander, ebenso der Tonfall der Dialoge oder wer wen unterbricht. Das Ziel ist es, den Einfluss einer Person als Wirkmoment zu nutzen, etwa für die Ausbreitung von Innovationen. Ursprünglich stammen solche Analysen aus dem viralen Marketing, das wissen will, welche Kunden so einflussreich sind, dass sie ihre Freunde vom Kauf eines Produkts überzeugen können.
Der Tokioter Mischkonzern Hitachi nutzt für das Stressabbau- und Pausenmanagement das «Business Microscope» (auch «Happiness Meter»). Hierbei handelt es sich um einen Mitarbeiterausweis, der sich wie eine Halskette umlegen lässt. Das Business Microscope misst die Gehirnwellen auf Stress und Müdigkeit hin. Gestützt darauf passt Hitachi die Pausenpolitik an. So will der Konzern herausgefunden haben, dass sich die Produktivität verdreifache, wenn Gleichaltrige zusammen die Pausen verbringen. Derweil hat die Bank of America dank ihren Ausweisen von Humanyze entdeckt, dass die Kündigungsrate sinkt, wenn Arbeitsteams gemeinsam Pause machen.
IBM wertet im Projekt Enterprise Social Pulse die Gefühlslage im Unternehmen aus basierend auf frei zugänglichen Texten der Mitarbeiter auf internen und externen sozialen Netzwerken und Umfragen (enterprise-oriented employee sentiment analysis). Bezweckt wird, die kollektive Stimmung in einem weltweit tätigenGrossunternehmen in Echtzeit einzufangen und Sorgen aktiv anzusprechen.
Zur Prognose der Personalfluktuation analysieren Arbeitgeberinnen die Daten ausgeschiedener Mitarbeiter. Aus diesen Erkenntnissen ergibt sich die Feststellung, welche Lebens- oder Beschäftigtensituation typischerweise zu einer Kündigung führt und dass sich der Grad der «inneren Kündigung» der bestehenden Belegschaft abschätzen lässt. Um dem entgegenzuwirken, entwickeln Unternehmen wie SAS, Microsoft und Xerox für wertvolle Mitarbeiter Anreizprogramme. Dabei sollen Weiterbildung und Teilhabe an der Unternehmensentwicklung den Mitarbeiter stärker an die Unternehmung binden. Conagra Foods setzt auf Anerkennung und nichtmonetäre Belohnungen.
Um den Entscheid über eine Beförderung auf eine informierte Grundlage zu stellen, werden Stimm- und Gesprächsanalysen durchgeführt. Es gibt Smartphone-Applikationen, die eine 360°-Rückmeldung von Arbeitskollegen, Vorgesetzten und Kunden erlauben. Solche Feedback-Daten gibt es immer mehr, weil grosse Unternehmen wie General Electric, Schneider Electric, SAP, Adobe, Accenture oder Deloitte Consulting von traditionellen Jahresgesprächen zu ständigen Feedbacks wechseln.
Eine Software kann aber geradeso gut die Beendigung des Arbeitsverhältnisses vorschlagen: Eine kritisch zu beurteilende Software sieht keine Zukunft für alle Mitarbeiter, die in den letzten fünf Jahren nicht befördert wurden. Bridgewater Associates, einer der weltweit grössten Hedgefonds mit Sitz in den USA, setzt auf das Verwaltungssystem Principles Operating System (PriOS), das für die automatisierte Einstellung und Entlassung von Mitarbeitern oder die Bewertung gegensätzlicher Perspektiven bei Meinungsverschiedenheiten im Team verantwortlich sein soll. Der Hedgefonds will auf diese Art jeden Einfluss von Emotionen und Stimmungen auf Investitionsentscheidungen vollständig ausschliessen.
2.3.7 Zwischenfazit und Vorbehalte zur Klassifizierung der Verwendungszwecke
Eine Zusammenstellung der verschiedenen Verwendungszwecke und Anwendungsformen von People Analytics wie vorliegend hat es, soweit ersichtlich, bisher nicht gegeben. Dieser neue Beitrag zur Forschung ist aber erforderlich, um dem Leser die Dimension des Forschungsobjekts vor Augen zu führen: Es gibt eine unfassbare Variationsbreite von People Analytics-Angeboten, verteilt über alle Berufe. Produktlisten bleiben stets unvollständig, da sich der Markt laufend entwickelt.
Die vorgenommene heuristische Klassifizierung (Rekrutierung – Leistungssteuerung – Compliance-Management – Arbeits- und Arbeitsplatzgestaltung – Mitarbeiterbindung) dient der Praktikabilität und Abstrahierung, um mit dem begrenzten Wissen Aussagen über das Phänomen der Personalanalysen als Ganzes zu formulieren. Andere Autoren nehmen eine andere Kategorisierung vor.
Die gleichen Anwendungen lassen sich teilweise für mehrere Kategorien gleichzeitig einsetzen: Das (unter Leistungssteuerung erwähnte) Flugzeug-Flottenverwaltungs-System FES findet auch Verwendung, um die Einhaltung interner Richtlinien zu kontrollieren, beispielsweise ob die Piloten Anweisungen befolgen, den Benzinverbrauch beim Start ab 500 Meter Höhe zu reduzieren (Compliance). Die elektronische Standortübermittlung ausserhalb des Betriebsgeländes (Leistungssteuerung) ermöglicht die Verhinderung von Diebstählen und die Aufzeichnung der Fahrzeiten zum Arbeitnehmerschutz (Compliance). Der intelligente Teppich (Compliance) könnte für identifizierte Personen das Licht in einem Raum einschalten oder Türen automatisch öffnen (Arbeitsplatzgestaltung). Exoskelette dienen vermeintlich dem Gesundheitsschutz, indem sie die Rückenhaltung beim Heben von Lasten vorgeben (Compliance und Arbeitsplatzgestaltung); aber ebenso lässt sich genaustens überprüfen, wie viele Lasten der Arbeitnehmer täglich hochhebt (Leistungssteuerung). Schliesslich beinhalten Prognosen zur Personalfluktuation (Mitarbeiterbindung) auch einen Informationswert im Hinblick auf die künftige Personalplanung (Rekrutierung).
Nach der vorliegend vertretenen Einschätzung sind die meisten der beschriebenen People Analytics-Lösungen in der Schweiz wirtschaftlich umsetzbar. Einige davon mögen futuristisch klingen, so etwa die Gehirn-Chips zur direkten Kommunikation von Mensch zu Mensch. Die Technologie setzt den Verwendungszwecken aber grundsätzlich keine Grenzen. Daher ist zu untersuchen, wie es um die gegenwärtige und mögliche künftige Verbreitung von People Analytics steht (dazu sogleich).
Gabriel Kasper in: People Analytics in privatrechtlichen ArbeitsverhältnissenVorschläge zur wirksameren Durchsetzung des Datenschutzrechts; 2021; Dike Verlag, Zürich
https://creativecommons.org/licenses/by-nc-nd/3.0/ch/
DOI: https://doi.org/10.3256/978-3-03929-009-3
Zur einfacheren Lesbarkeit wurden die Quell- und Literaturverweise entfernt.